
Publications
For an updated list of publications please refer to my Google Scholar profile. * denotes equal contribution
 | Inductive Biases For Higher-Order Visual CognitionShashank Shekhar Master's Thesis, 2022paper /We demonstrated state-of-the-art results in generating scene graphs from natural images by using a sequential subject->predicate->object generation using a transformer encoder on object bounding boxes derived using a detection model. |
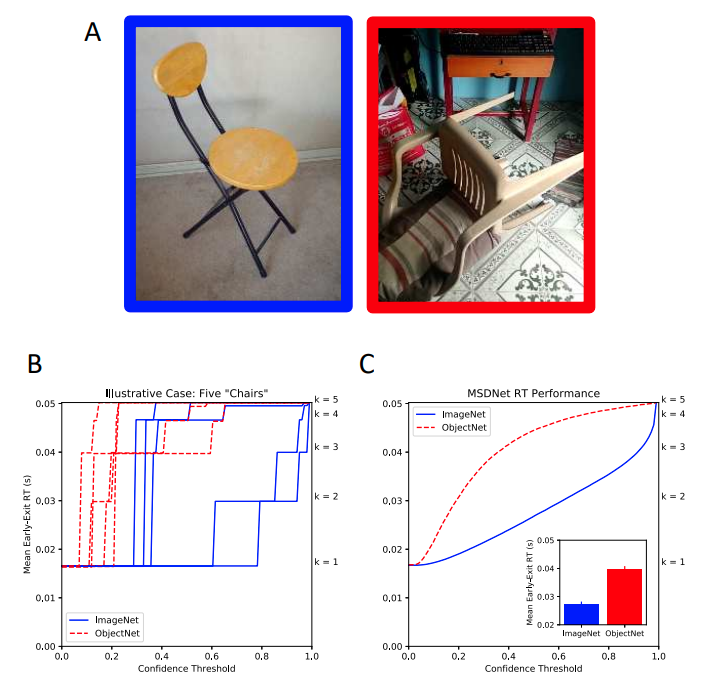
 | Neural response time analysis: Explainable artificial intelligence using only a stopwatchEric Taylor*, Shashank Shekhar* , Graham W Taylor Applied AI Letters, 2021paper / video /We extended our work on Neural Response Time analysis from CVPR-W 2020 with an additional experiment showing that NRTs are sensitive to intra-class variations, yet can be used to reliably inform between intra-class variations between objects. |
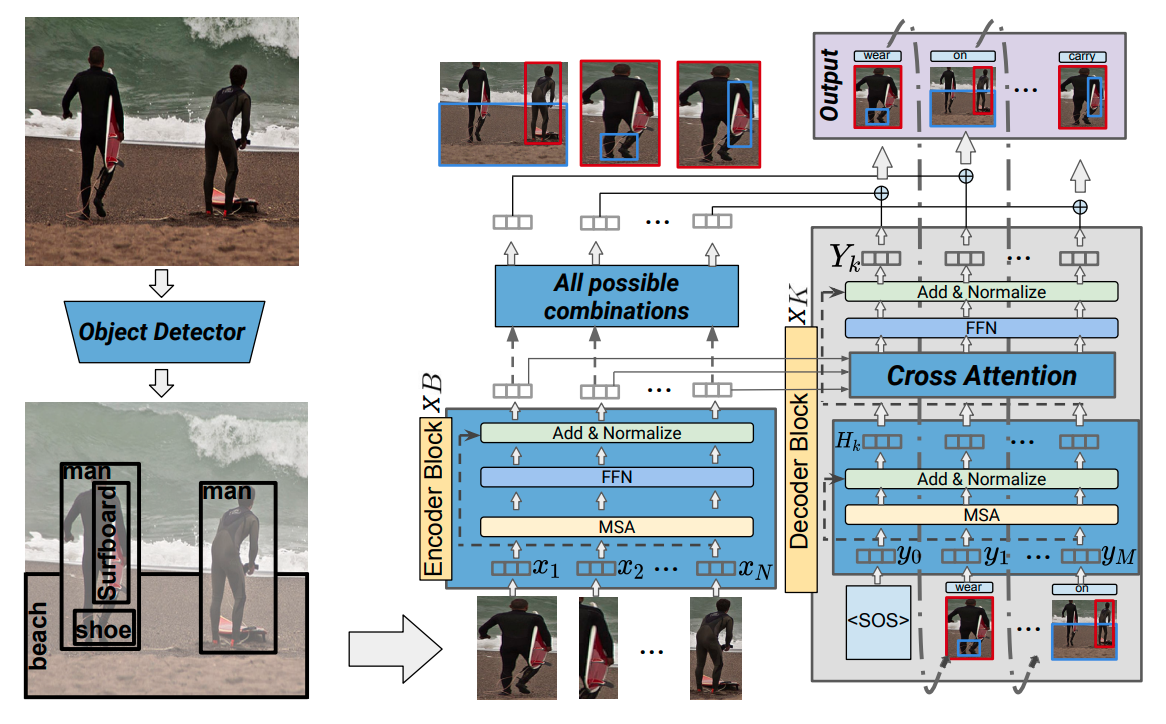 | Context-aware Scene Graph Generation with Seq2Seq TransformersYichao Lu, Himanshu Rai, Jason Chang, Boris Knyazev, Guangwei Yu, Shashank Shekhar , Graham W. Taylor, Maksims Volkovs International Conference on Computer Vision, 2021paper / code /We demonstrated state-of-the-art results in generating scene graphs from natural images by using a sequential subject->predicate->object generation using a transformer encoder on object bounding boxes derived using a detection model. |
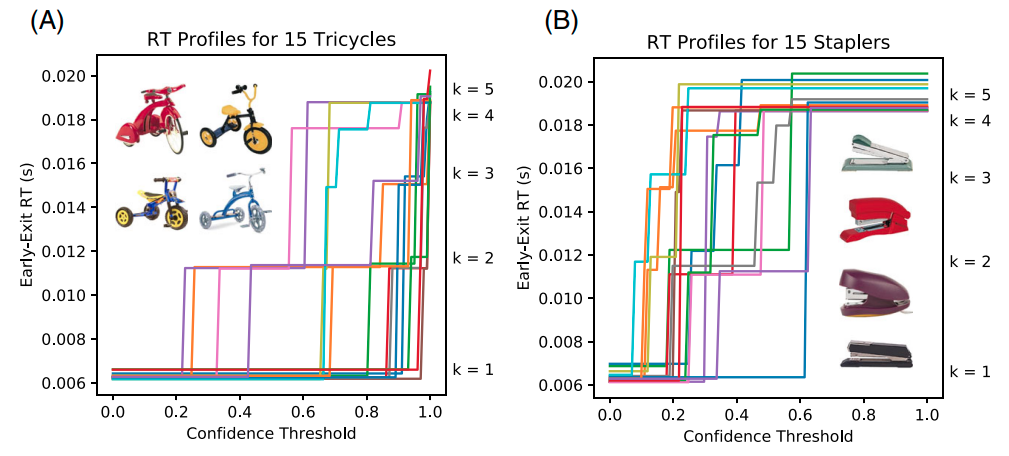
 | Response Time Analysis for Explainability of Visual Processing in CNNsEric Taylor*, Shashank Shekhar* , Graham W Taylor Computer Vision and Pattern Recognition (CVPR) Workshop, 2020paper / video /We adapt response time evaluation in human psychophysics for deep learning to calculate Neural Response Times (NRT) by profiling dynamic DNNs. We verify that NRT is able to corroborate known effects about the feature space composed by object recognition models when tested on OOD view points. We further demonstrate that NRT can be used to causally verify Scene Grammar effects in identifying semantic and syntactic inconsistencies across visual scenes. |
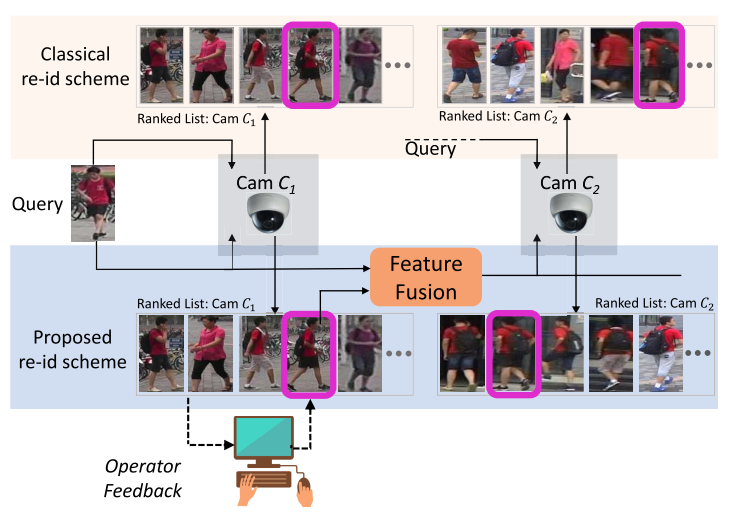 | Operator-in-the-Loop Deep Sequential Multi-camera Feature Fusion for Person Re-identificationKL Navaneet, Ravi Kiran Sarvadevabhatla, Shashank Shekhar , R Venkatesh Babu, Anirban Chakraborty IEEE Transactions on Information Forensics and Security, 2019paper /We developed a human-in-the-loop system to rank image retrieval results from an image recognition CNN and then merge them with human choice for person re-identification. Our method showed consistent improvement in performance across 6 cameras compared to only relying on model insights. |
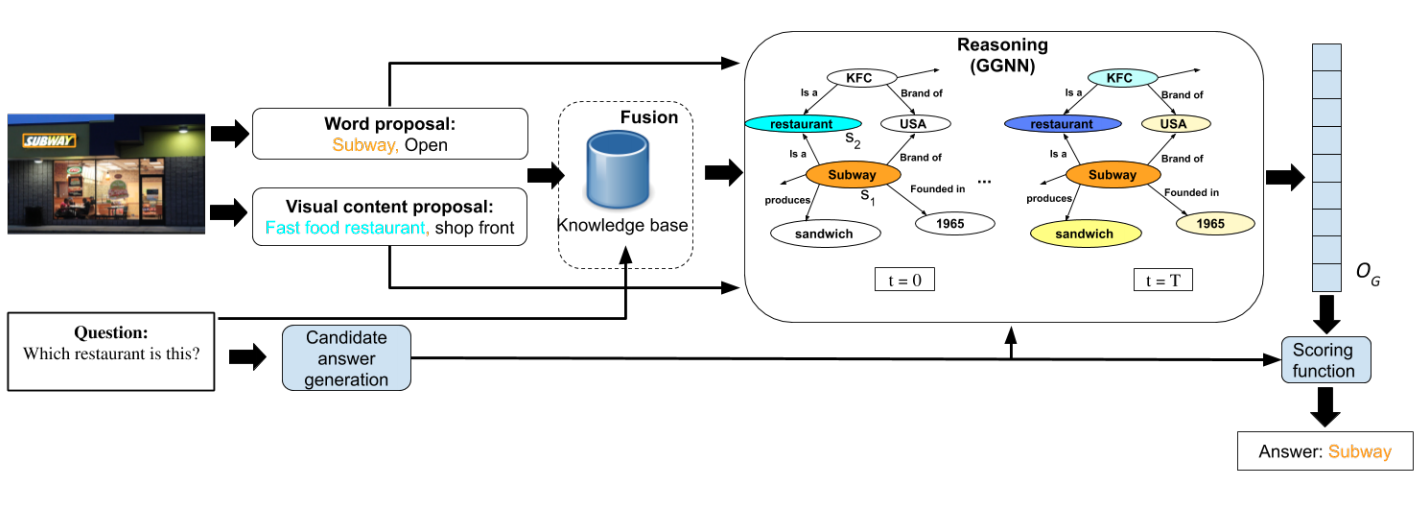 | From Strings to Things: Knowledge-enabled VQA Model that can Read and ReasonAjeet Kumar Singh, Anand Mishra, Shashank Shekhar, Anirban Chakraborty International Conference on Computer Vision, 2019paper / website /We released the first dataset for Visual Question Answering (VQA) that requires traversing an external knowledge-graph as well as understanding scene-text through Optical Character Recognition (OCR). We also proposed a Graph-RNN based approach for VQA with external knowledge and demonstrated state-of-the-art results. |
 | OCR-VQA: Visual question answering by reading text in imagesAnand Mishra, Shashank Shekhar , Ajeet Kumar Singh, Anirban Chakraborty International Conference on Document Analysis and Recognition, 2019paper / website /We released the first dataset for Visual Question Answering that requires understanding scene-text through Optical Character Recognition (OCR). |
 | Road Damage Detection And Classification In Smartphone Captured Images Using Mask R-CNNJanpreet Singh*, Shashank Shekhar* IEEE BigData Cup 2018 workshop, 2018paper / code /We fine-tuned a Mask R-CNN trained on MS-COCO dataset to detect and classify road damage in real-world images of roads taken from smartphones. |